Changing How We Detect Diseases in Medical Images with Quanvolutional Neural Networks
Tomorrow is my friend Lia’s birthday. To wish her, I need to find the prettiest photo of her to upload to my social media platforms. I haven’t revealed how much I enjoy taking photos, so I have 10,000+ on my camera roll that I need to sift through to find the ones with Lia. I’m dreading to sit down and find a picture of her because I know it’ll take a while.

Thankfully, in 2016, Apple solved my problem through streamlining the process of locating and grouping images. Now, I can head on over to my assortment of albums, where my photos are automatically sorted by people. I’ll be able to effortlessly browse through the 529 pictures of Lia, and to choose one based on my personal preferences.
But…. how?
Diving Deeper into Deep Learning: Convolutional Neural Networks
Think about how we identify who or what is around us. Currently, I’m typing this on what I know as a laptop, I’m sitting on a chair and there’s a bed behind me. It takes less than a second to identify majority of the objects around me, as my brain has been ‘trained’ to know what the names for each of these are — we call this learning.
So, how does the little computer in our pockets sort out our images according to people who’s name it doesn’t even know?
*spoiler alert*
It’s Convolutional Neural Networks.
Convolutional Neural Networks (CNNs) are a type of deep learning model — which is a subset of machine learning that involves training artificial neural networks with multiple layers to recognize patterns and extract insights from large datasets. CNNs can analyze and classify visual data, such as images or videos…. think of them like a computer’s eyes.
The word ‘neural’ in Convolutional Neural Networks is pretty significant. CNNs are a type of Neural Networks — which emulate the behaviour of the human brain. They work by passing information from dendrites to neurons, which then relay this information through connections between them. It’s kind of like how our brain cells communicate with each other to help us understand and interpret the world around us.
Here’s what the process of a CNN looks like…

…let’s break it down.
As you can see above, the Convolutional Neural Network model is built with multiple different layers — which can be categorized as input, hidden and output layers.
We start off with the input layer. This is the layer that receives an image or a batch of images as an input. It’s responsible for preprocessing the input data and translating it into a format that can be processed by the subsequent layers — whether this means resizing, normalization or data augmentation.
The input layer is typically a 3D tensor (a mathematical representation of a multi-dimensional array of data) with height, width and channels as the dimensions. Height and width are obviously the pixel size of the image but channels refers to the number of colour channels in the image.
For example, if we were working with a 28x28 image that is black and white, our input tensor dimensions would look like: 28, 28, 1
Now, we’re entering all the hidden layers, which are the layers in between the input layer and output layer and are responsible for feature extraction that is relevant to the classifications you want to make.
Next up, the data is sent on over to the convolutional layer. This is when the learning begins. It’s a fundamental building block of a CNN that performs feature extraction from the input images. This is done through applying a set of learnable filters, also called kernels, to the input image in order to produce output feature maps that highlight the various patterns and features present in the input.
Mathematically, to produce a feature map, a filter — which is a small matrix of weights — is put over the input image, and the dot product between the filter and the input image patch at each position is calculated, which results in a single output value for each position in the feature map.
Visually, it looks a little something like this…

Once we’ve got our output feature map, our computer is a little more confident in the features it needs to identify in order to classify the set of images. Except, it’s still a working process.
The activation layer is next, another important part of CNNs. It introduces non-linearity into the neural network by applying a mathematical function to the output of the previous layer. This allows the CNN to expand beyond modelling only linear relationships, so that it can model complex data easily. There’s many popular activation functions, but for CNNs, ReLU and sigmoid are the most commonly used.

We now move onto the pooling layer of the CNN, which comes right after the convolutional layer. This reduces the spatial size of the input feature maps, while keeping all of its important features. Through this, we can reduce the computational cost of the network and prevent it from getting too good at recognizing the training data but not being able to work well on new data.
The pooling layer divides the input feature map into smaller rectangular regions, which are called pooling regions. Then, it computes a single output value for each region by using a pooling operation such as max pooling or average pooling.

As we reach the end of the model, we arrive at the fully-connected layer. It’s the last of the ‘hidden layers’ and is placed after the convolutional layer, activation layer, and pooling layer. This layer is responsible for the final classification of the image.
The fully connected layer receives a flattened version of the output from the previous layer as an input and then uses a set of kernels to calculate a set of output values. These output values can be interpreted as different labels, based on the task you’re trying to perform.
And, finally, we exit the hidden layers and are able to reach the final output layer in our model. It’s the final layer of a neural network and is responsible for producing the final output of the model.
The output of neurons within the output layer is also compared to the ground truth labels to compute a loss value, which measures how well the model is performing on the given task. The goal of training the neural network is to minimize this loss value by adjusting the weights of the model.
That’s the inner-workings of a convolutional neural network, which is exactly what your phone uses to categorize the people and objects in your photos. The ‘eyes of our computers’ are truly so powerful and can eliminate so many manual tasks for humans.
CNNs Improving The Medical Diagnosis Process
I know we’ve been talking about sorting through photos of our friends and sorting pictures of cats and dogs, but the impact of convolutional neural networks extends beyond that.
Diagnosis isn’t an easy or a definitive process. Medical imaging techniques such as X-rays, CT scans, and MRI produce large amounts of data that require expert analysis to identify any potential health issues. And, interpreting medical images can also be challenging, when the abnormalities are subtle to difficult for the human eye to detect.
Currently, when you take a CT test, it takes at least 24 hours to receive your results as a radiologist has to manually view and analyze all 100+ images. I should also mention that the error rate is ~5%, which may not seem like a lot but can severely harm patients.
Here’s where convolutional neural networks enter the picture, as they’ve shown great promise in improving the medical diagnosis process through a more efficient and more accurate analysis of medical images.
Using our knowledge of CNNs, we already know that they can be trained to look for certain features in medical images that are indicative of a particular disease or condition. Also, this could potentially enable earlier and more accurate diagnoses.
The only problem — yes, there’s a catch — is that a CNN with a fully-connected network structure uses a large amount of memory. Loads of data leads to slower computation time and greater computation power. And, depending on the number of images and classes, the layer could increase — which leads to an increase in the complexity analysis of the model. Long story short, it takes a very long time to train Convolutional Neural Networks, when working with big datasets.
Let’s Enhance it Further By Adding in the Quantum…
This is why quantum computers exist… to solve all your big-data problems.
If you’re not too familiar with quantum computing and its principles, I’d recommend giving this article a read before you read below!
Actually, I (sort-of) lied. Quanvolutional Neural Networks is a hybrid model that has both classical and quantum components, but the quantum aspects of it hold tremendous value and can fix our problem of training being slow.
By the way… Quantum + Convolutional Neural Networks = Quanvolutional Neural Networks
The goal behind Quanvolutional Neural Networks is the same as Convolutional Neural Networks. You’re looking to extract the most relevant features in an image, in order to determine patterns that are involved.
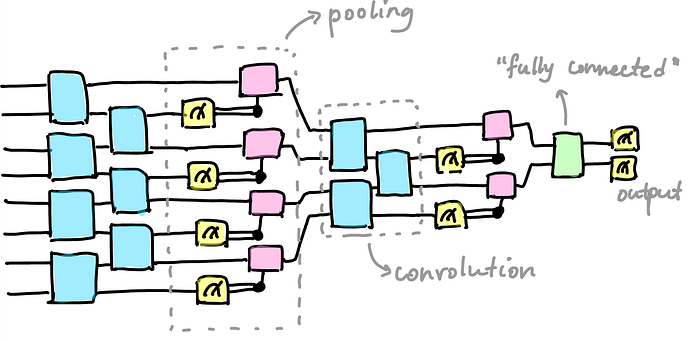
The Quanvolutional Neural Network is built in the exact same format as a CNN, except each layer is represented as a quantum circuit… which explains why it looks a little different. But, there’s still the order of convolutional, pooling, and fully-connected layers.
Since we know that convolutional layers are responsible for most of the feature extraction from the image, it makes sense that in quanvolutional neural networks, there’s a quanvolutional layer.
How this works is that the input data is translated into a quantum representation through encoding the classical data in a quantum register. The most common techniques used to do that are amplitude encoding and qubit encoding…
- Amplitude Encoding involves mapping classical data onto the amplitudes of a quantum state. We use the input data’s binary representation to provide it with a quantum representation of its amplitude, as in quantum mechanics the state of a quantum system is described by a wave function. The amplitude is usually a complex number that determines the probability of measuring that state when observed. In this case, the classical data is translated into an amplitude within the quantum system depending on its binary value. For example, if our input data is 01, we might assign 0 as the small amplitude (small complex number with a small absolute value) and 1 as the larger amplitude (large complex number with a large absolute value).
- Qubit Encoding involves mapping classical data onto the states of qubits in a quantum register, which is done through setting the quantum states to correspond with the binary representation of the input data. For example, let’s say that our input data is 01, in the quantum register we can represent it with the state of the first qubit as |0⟩ and the state of the second qubit as |1⟩.
Either way, you’re making the data read-able for the quantum computer.
Once the input state is prepared using either of these techniques, a quantum circuit applies many different quantum gates to perform the convolutional operations that we would in a CNN, except this is done through quantum gates (which are individual unitary operations) that apply a series of transformation on the quantum state. Through this, we extract the most important features of the input in a quantum context.
A common quantum gate that’s used in quanvolutional layers is the Controlled-U gate, where U is a single-qubit unitary operation. Basically, a math operation that changes the state of the system. The Controlled-U gate acts on two qubits, where the first qubit is the control qubit and the second qubit is the target qubit. If the control qubit’s state is |1⟩ then the gate applies the unitary operation to the target qubit, which indicates the data is relevant and extracts it. The quantum gates do the exact same thing our kernels did in CNNs.
By the way, a control qubit is used to control whether the operation is applied or not and the target qubit is where the operation is applied!
Once we’ve applied the set of Controlled-U gates to each sub-register within your main quantum register, we can combine the results of the quantum states to form the output of the quanvolutional layer. We can repeat this process as many times as needed to extract all features needed… after all, quantum computers are much faster.
Through taking advantage of phenomenas such as quantum parallelism and interference through Controlled-U gates, we can create more precise feature extraction which leads to more accurate results. This is because the gate can implement more complex operations on the quantum data than a kernel can in a regular CNN.
Also, the exponential speed-up cannot be ignored.
For reference, if we followed everything I just mentioned, the equations for the training time needed would look like this…
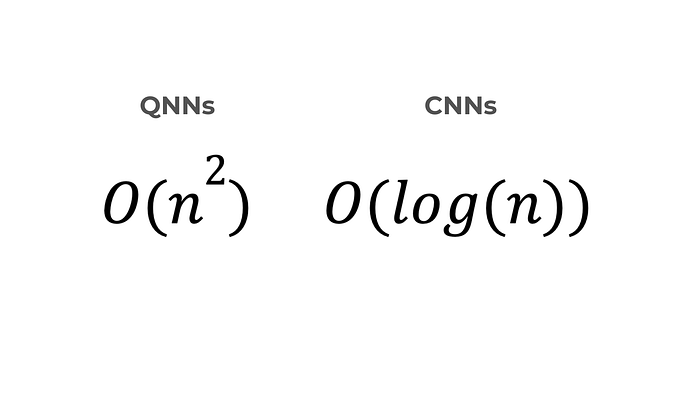
… which is a HUGE difference!
Anyways, once you’re done with your quanvolutional layer, you can move onto your quantum pooling layer. This is where we reduce the spatial dimensions of the input quantum data while preserving all the important features our quanvolutional layer picked out, so that our QNN can become more efficient and scalable. It’s just like a traditional pooling layer in a CNN, except this time we use a quantum circuit to extract certain statistics from the input quantum state, instead of using a classical function.
We do this through applying a series of unitary operations (we mostly use Hadamard gates for this) to the input quantum state of the pooling layer, and then follow it with a measurement of the output qubits in the computational basis. These results from the observation can be used to calculate the desired statistics, which really depends on the specific pooling method we’re using for our dataset.
If that sounds a little confusing or tricky, think of it this way: If we were trying to calculate the mean of the input quantum state, we would measure each qubit and then calculate the mean of our qubits in their classical form.
Once we figure out this mean, we can construct our output state of the quantum pooling layer.
By doing this, we can achieve the model’s goal of constructing a lower-dimensional output quantum state while retaining all important features of the input data. This is important because it’s a problem that holds CNNs back from even higher accuracy values. Also, quantum pooling layers are able to extract higher-order moments of the input distribution, which allows for a more comprehensive characterization of the data than our classical pooling layers would give us.
We’ve got our quanvolutional layer and our quantum pooling layer, so of course, our quantum fully-connected layer is next. Here, our quantum fully-connected’s goal is to learn a non-linear function that maps the input quantum state to an output quantum state — so that we can finally classify our images.
The quantum fully-connected layer is the layer in the QNN that connects all of the input qubits to output qubits, so that our model can be its final inference on which class each image belongs to. This is done through the layer applying a series of parameterized (parameters set in place during training) unitary operations to transform the input quantum state into the desired output state. The most common gates we use to do this are single-qubit rotations, two-qubit controlled gates and multi-qubit entangling gates — all of which, manipulate characteristics of the qubit state to perform the desired transformation.
Once we’ve done that, the output of the quantum fully-connected layer is typically a probability distribution over the possible output states. So that means that our output is processed to collapse the quantum states into a classical bit string. Using these probabilities, our QNN can determine which class belongs to which probability statistics so that it can accurately predict whether or not an image is or has a particular object.
For example, if we had a QNN that was trained to classify between cats and dogs and the probability value of the output qubit looked like [02,0.8] where 0.2 is assigned to the ‘dog’ class and 0.8 is assigned to the ‘cat’ class, the model will predict that the image contains a cat with a 80% confidence rate!
Similar to Convolutional Neural Networks, our predicted outputs are compared to the true output, whether it be the accuracy or loss values of the model. Our final QNNs don’t always have to contain a quanvolutional layer, quantum pooling layer and a quantum fully-connected layer, and it’s very possible for the model to only have one of these with an entirely classical model. That depends on the dataset in question. But, regardless of how many quantum layers there are, our quantum-classical hybrid is so powerful towards enhancing the current state of Convolutional Neural Networks.
Closing Thoughts
Without a doubt, Quanvolutional Neural Networks are still in the development phase. They require so much more time to become a 100%
feasible solution, as quantum computing hardware fights its limitations. But, with the recent advancements in battling decoherence + error rates and finally reaching ‘step two’ of building quantum computers, the future of faster and more accurate neural networks to detect diseases in medical images isn’t far
When able to be used to its full potential, we can significantly impact medical imaging analysis, diagnosis, and treatment… and be apart of a world where diagnosis errors don’t harm patients and receiving results isn’t a long process.
Hey, I’m Priyal, a 16-year-old who’s ambition revolves around working on solving complex problems to meaningfully contribute to the world. If you enjoyed my article or learned something new, feel free to subscribe to my monthly newsletter to keep up with my progress in quantum computing exploration and an insight into everything I’ve been up to. You can also connect with me on LinkedIn and follow my Medium for more content! Thank you so much for reading.
